Agentic Data Engineering for Lakehouse & Spark
Actionable runtime intelligence to optimize cost, accelerate developer velocity, and improve data reliability.








THE DEFINITY PLATFORM
Agentic Operations for the Lakehouse
AI agents to optimize, fix, and upgrade pipelines – shifting from reactive alerts to proactive in-motion action
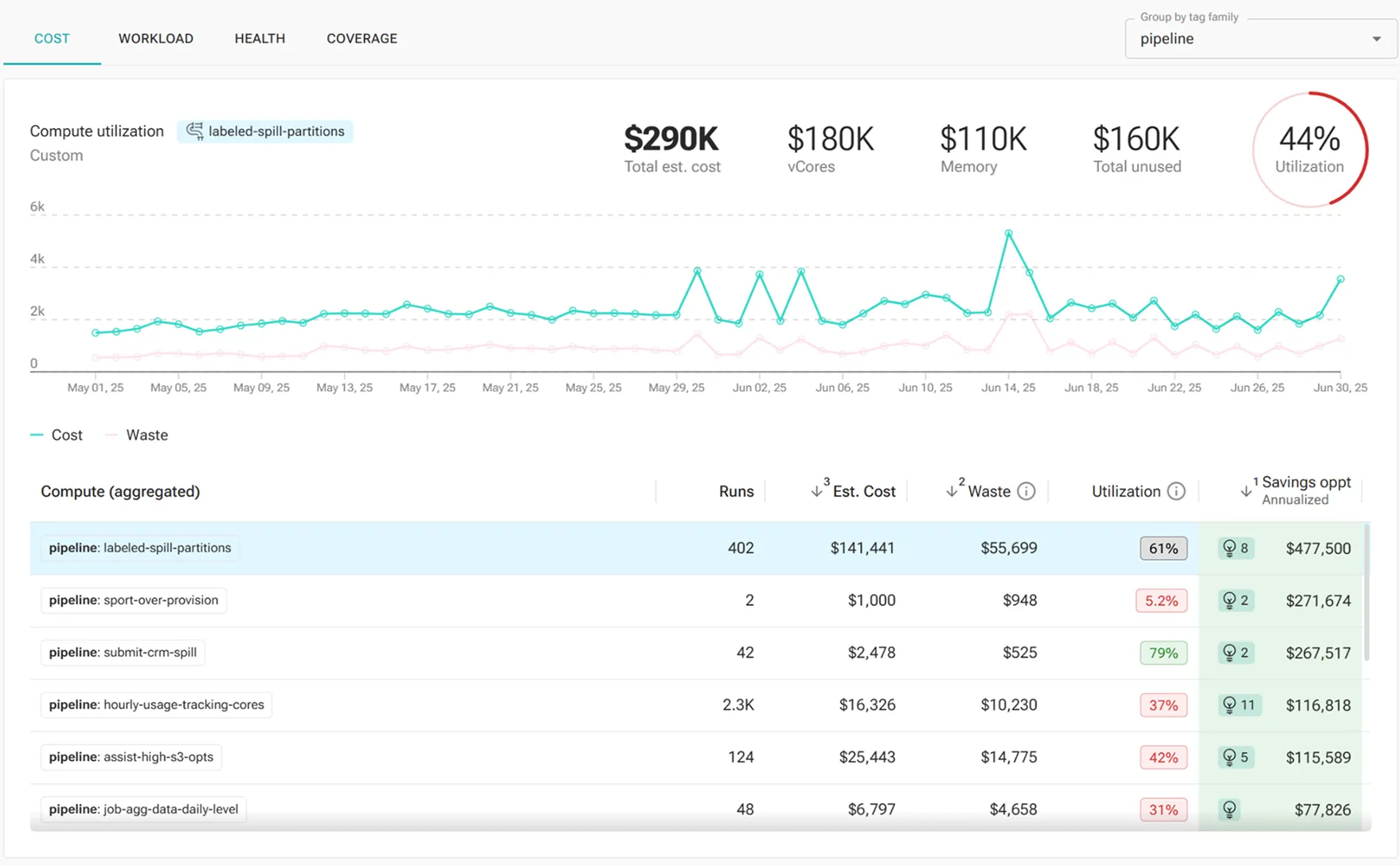
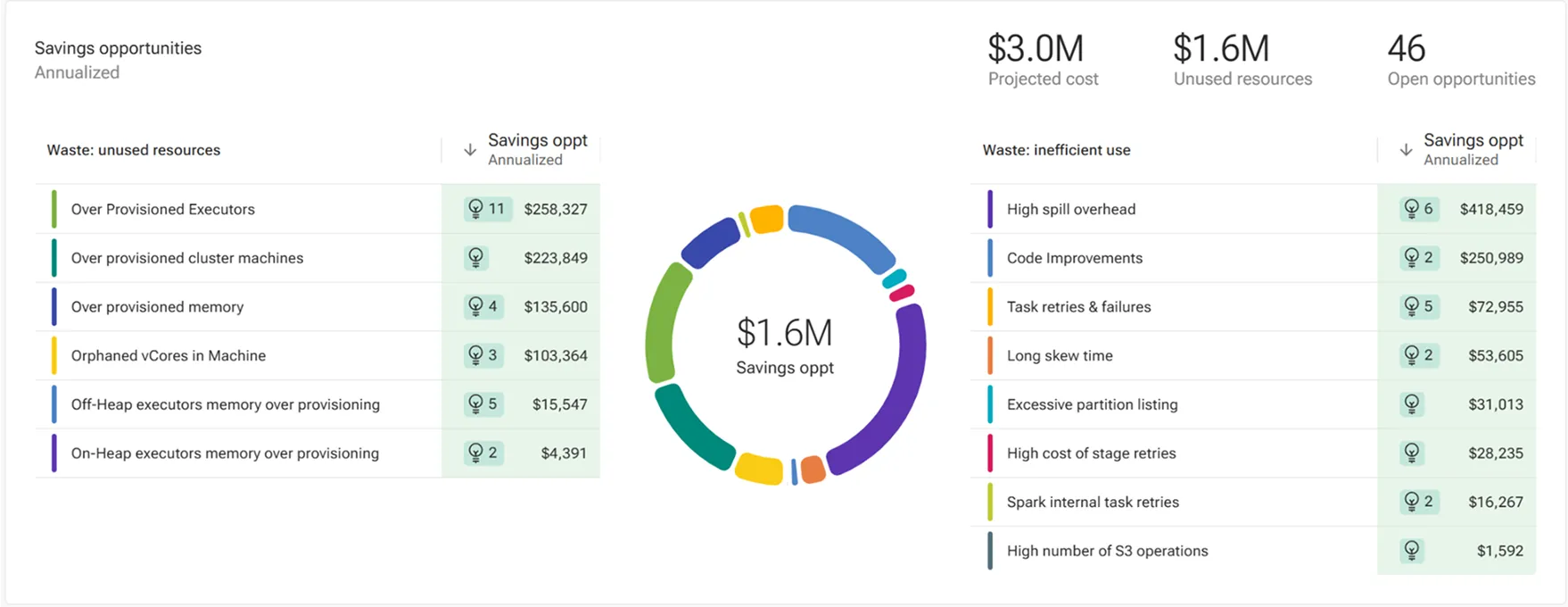
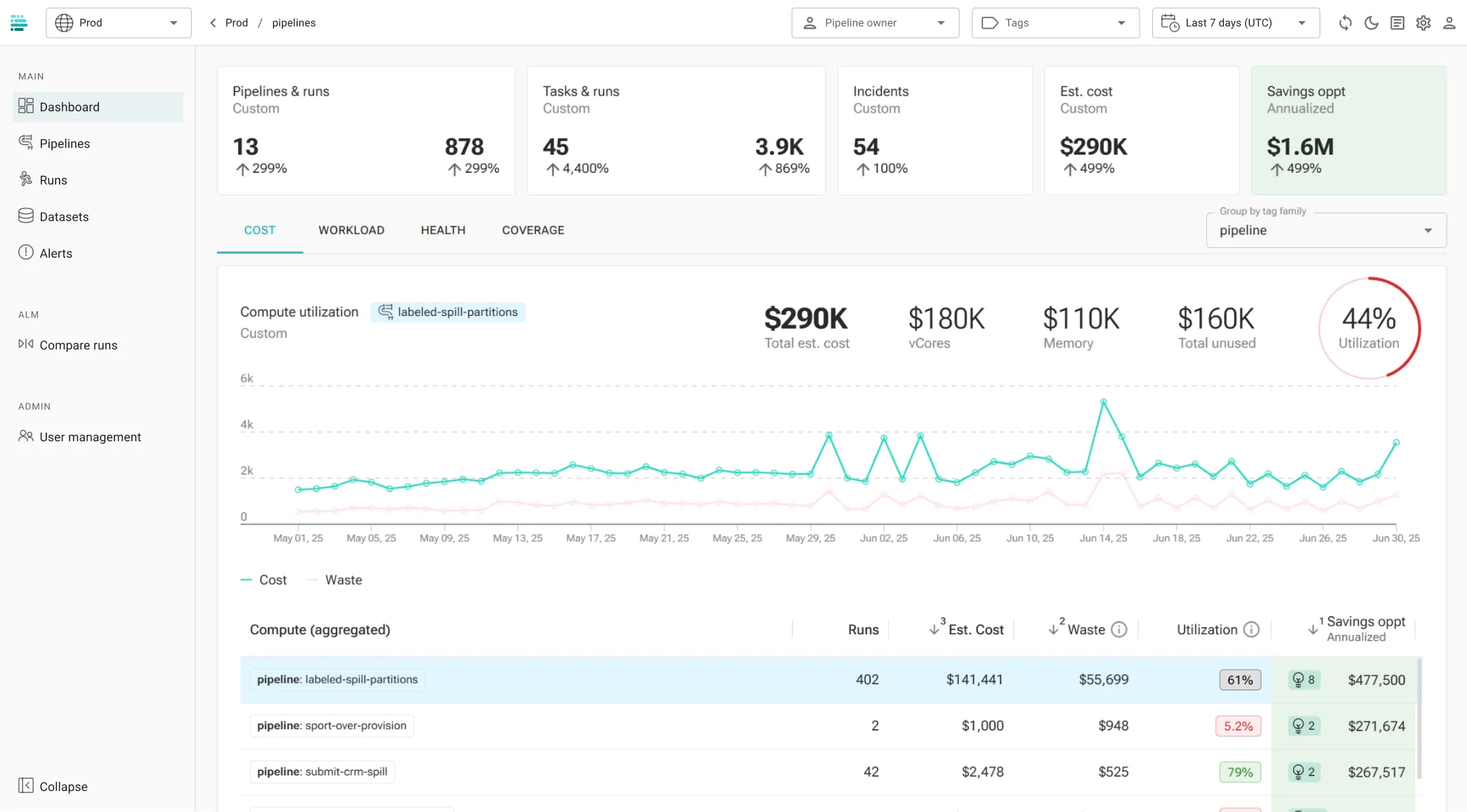
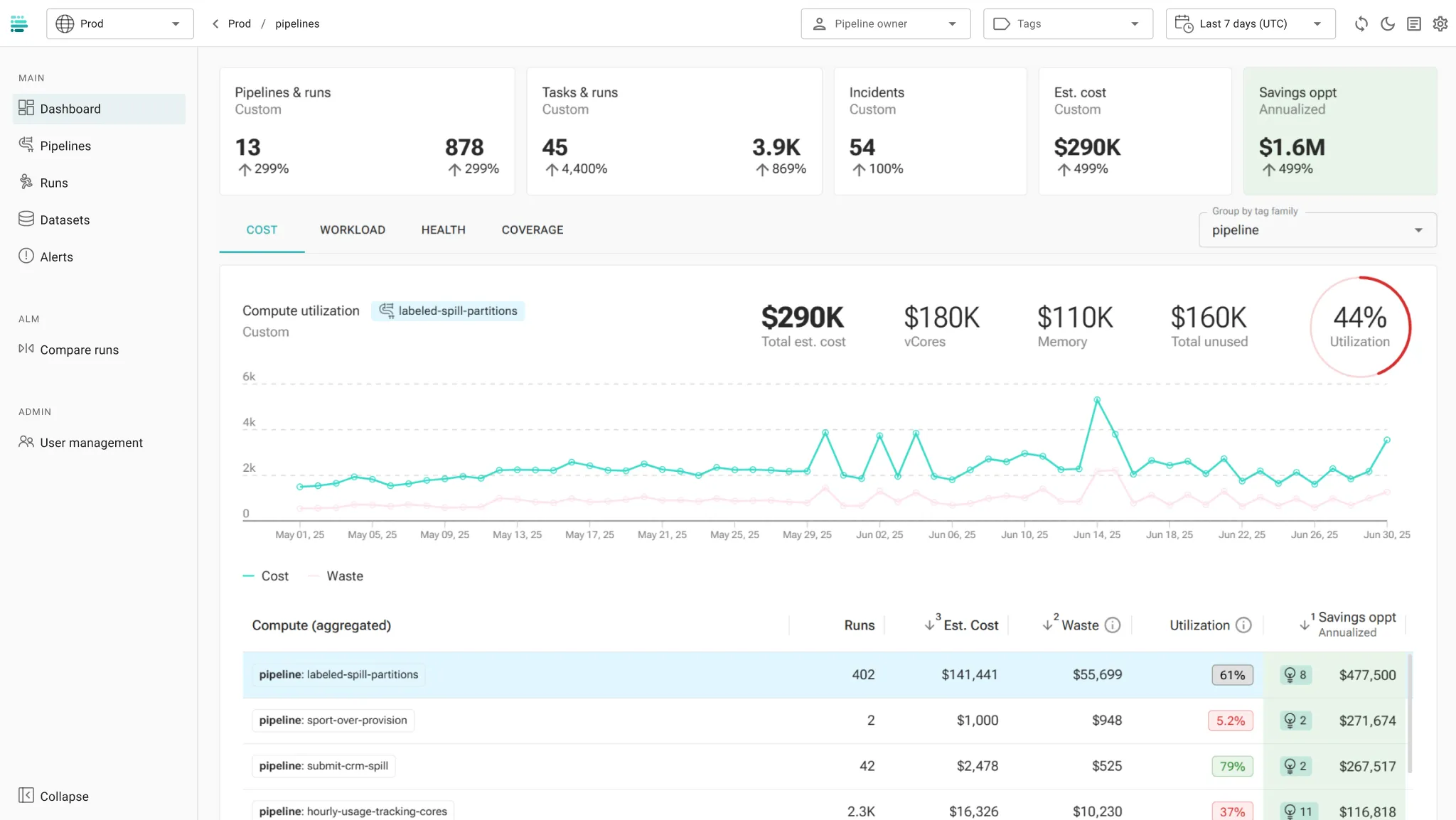
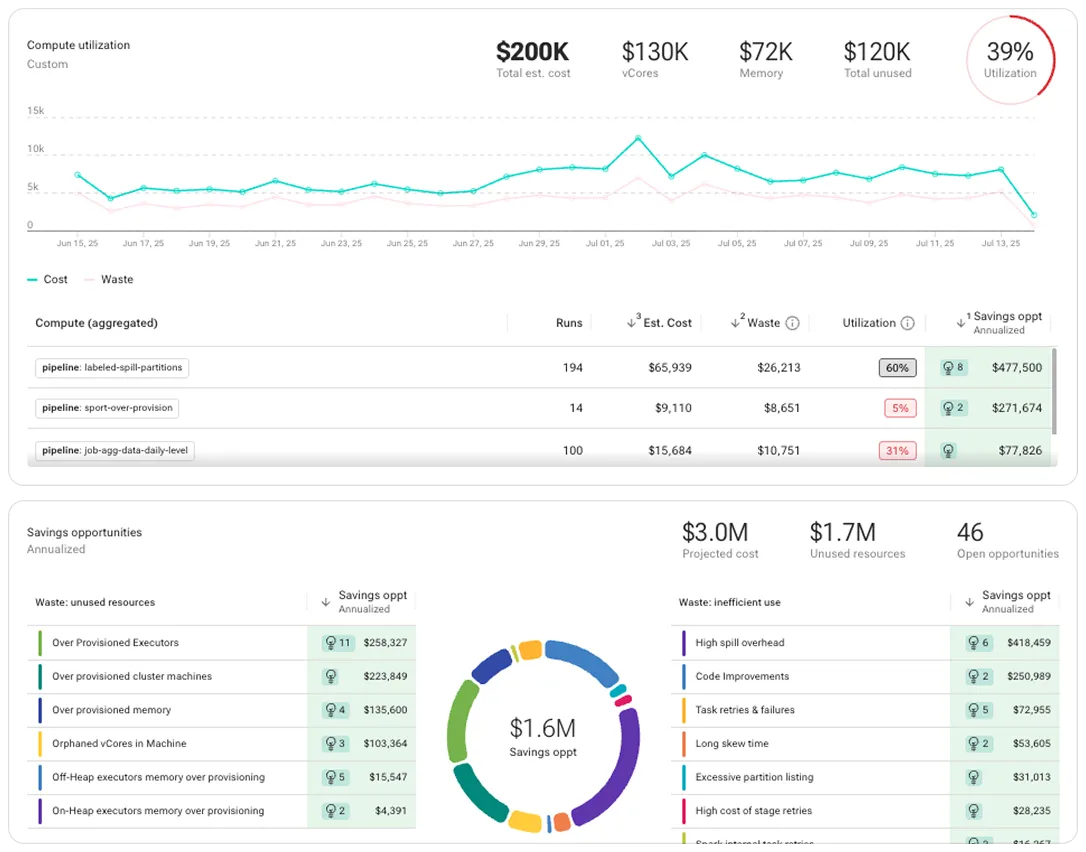
Cost Optimization
Cut platform cost at scale
Agentic recommendations and auto-tune to optimize jobs, clusters, and code

Pinpoint waste across compute, job execution, clusters, and pipeline code
Profile job performance over time, detect degradations, and identify optimization opportunities
Easily optimize at-scale with job-specific recommendations and 1-click auto-tuning

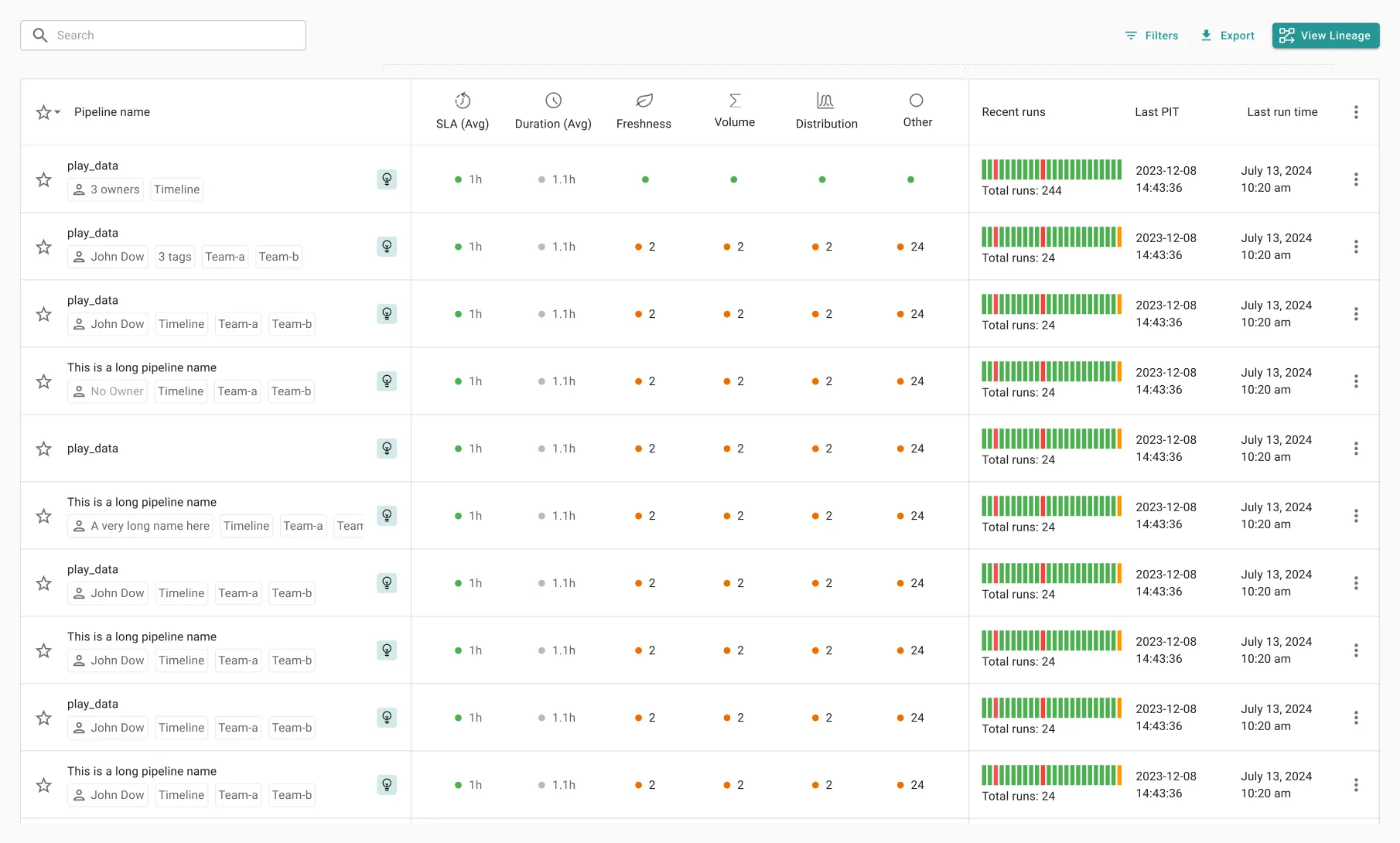
In-motion observability
Prevent issues in runtime
In-motion protection to prevent data quality, SLA, and pipeline incidents before they impact
Monitor your entire data stack, at every step – across data quality, pipeline health, and infra performance
Detect issues out-of-the-box with AI-powered anomaly detection
Prevent issues at runtime, with in-motion detection and automated run preemptions – even before pipelines run
Avoid issue propagation, business impact, troubleshooting effort, and wasted compute



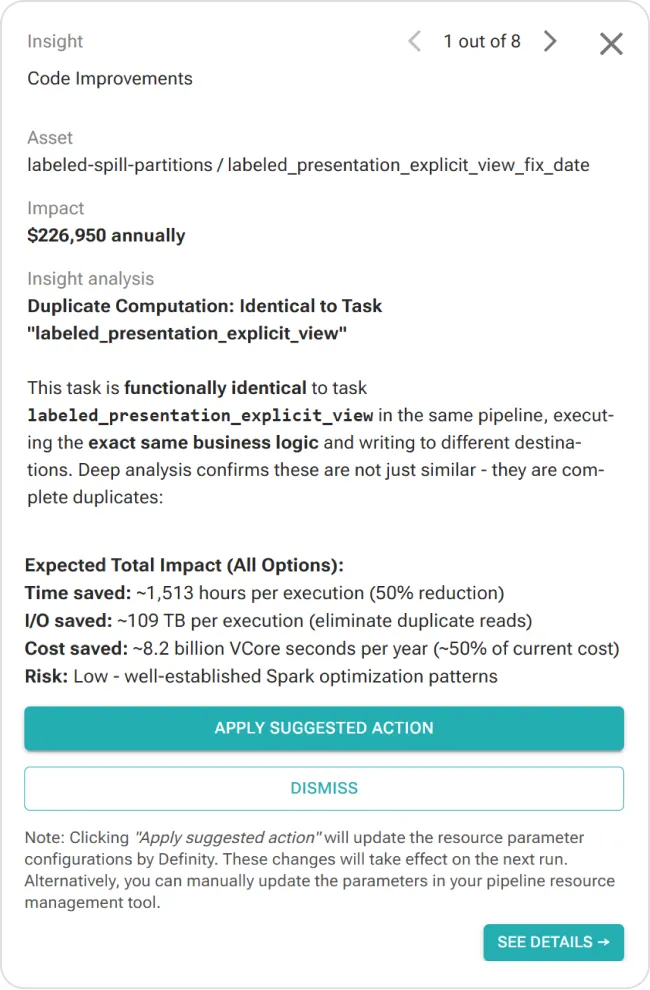
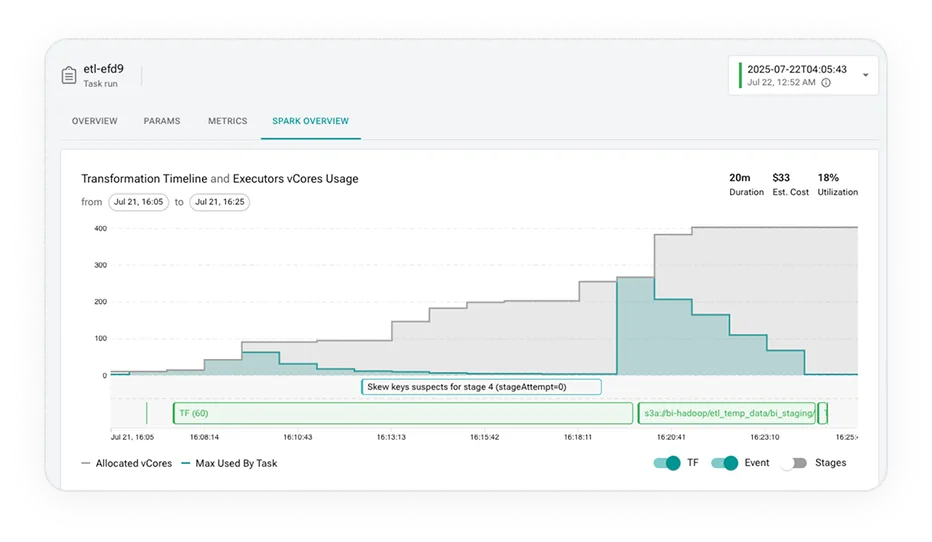
agentic troubleshooting
Resolve incidents 10x faster
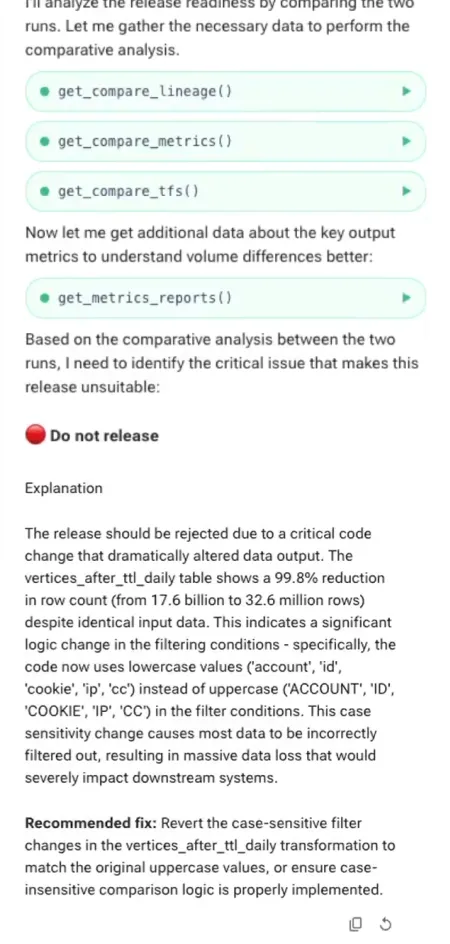
AI-powered insights based on full data-stack context to root-cause issues in minutes
Easily root-cause and resolve incidents with deep explainability, actionable insights, and context-aware AI assistant
Understand execution contextually – how data, pipeline, code, and environment operate together
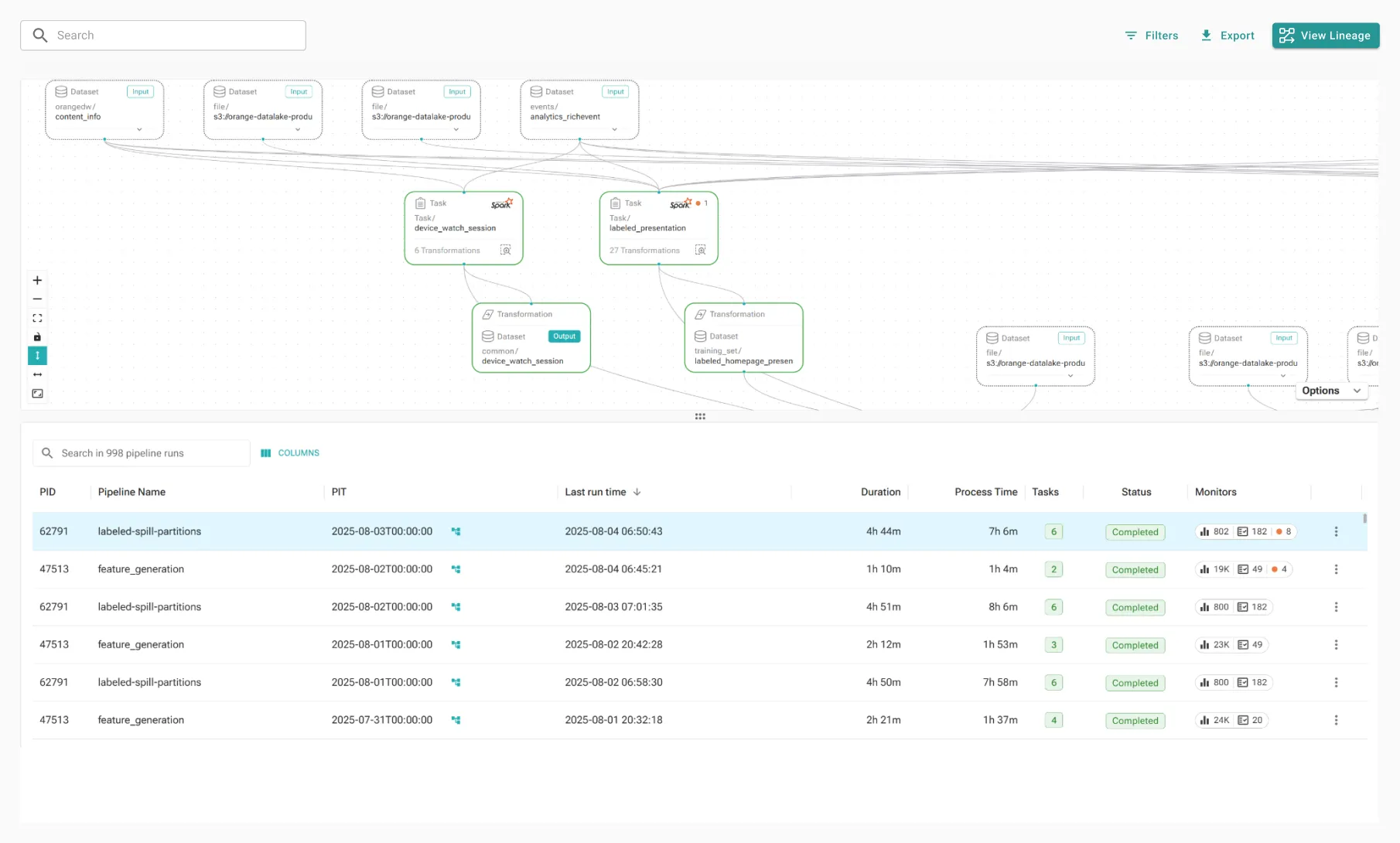
Trace issues to source and impact via deep data+job lineage, to avoid visibility gaps

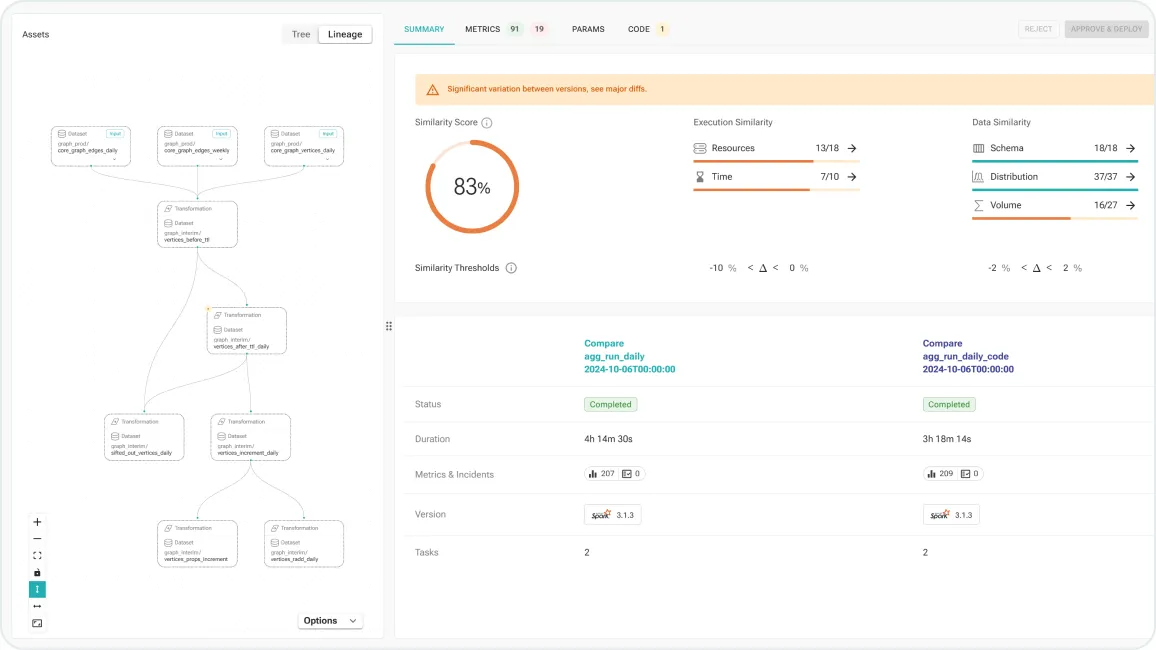
code changes validation
Auto-validate any code or platform change
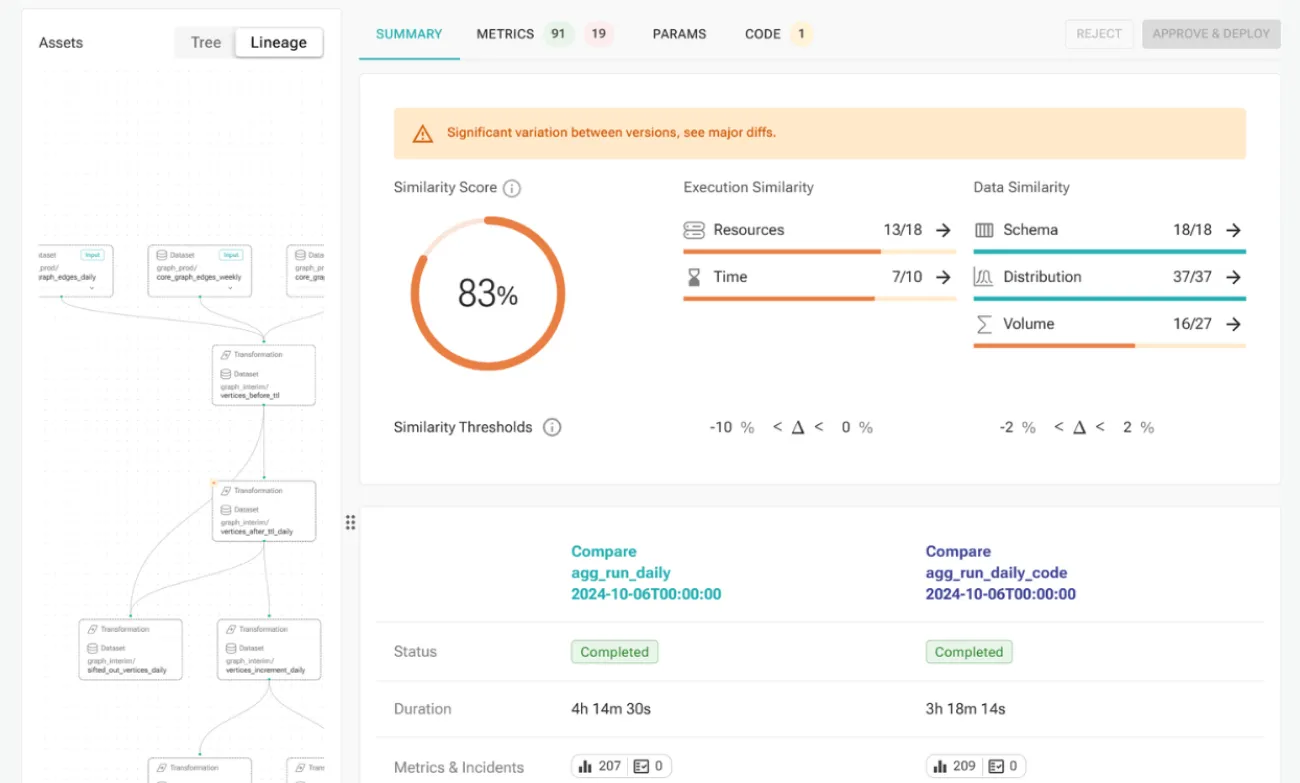
Agentic runtime-aware validation in CI, to accelerate code changes and platform upgrades
Automatically simulate runs in staging env without manual re-routing of jobs, data, or setup
Validate data reliability and job performance at every step – catch issues before hitting production
In case of issues – pinpoint to the specific changes in code, inputs, or environment
Accelerate testing and delivery cycles for pipeline code changes, platform upgrades, or migrations
Built for Enterprise Scale
Works Across Your Data Stack
Deploy anywhere – cloud or on-prem






Seamless installation. Fully secure.
Central one-time installation with zero code changes.
Scale observability across all workloads, in under 15 minutes
Secure by design – runs 100% in your environment, data never leaves
Measurable Impact In Production
Across enterprise data platforms
35%
infra cost reduction
90%
prevented data incidents
25%
increased dev velocity
50%
faster deploys & upgrades
CUSTOMER STORIES
Trusted by Leading Data Engineering Teams
Driving outcomes with definity




Boosts data developer velocity
With auto-optimizations and agentic RCA
"definity lets our engineers spend time where it matters the most"
Accelerates platform upgrade by 6 months
50% faster workload validations
"The future of our platform is AI Agents – definity sits at its core it with its runtime MCP, pipeline control, and auto-validation“
Prasanna, Sr Manager, Data Platform
Optimizes Spark platform cost by 44%
9x ROI captured in 5 months
"definity’s provided a turnkey solution to optimize Spark cost BIG TIME"
Dennis, Director of Data Engineering
Cuts EMR platform cost by 58%
Reducing pipeline run-times by 74%
“definity’s technology is clearly missing in the AWS stack”
Glenn, Sr Director of Data Platform
Learn more
Insights For Data Engineering Teams
.avif)
Demo
RCA with AI Assistant
Watch definity’s AI Assistant performs root cause analysis using real production runtime context

Blog
Agentic Data Engineering Is Coming – And Today’s Stack Isn’t Ready
AI-agents generating data pipelines will unlock 100x value. But this future inherently relies on runtime context that doesn't exist today.

Talk
DAIS 2025: How you could be saving 50% of your Spark costs?
Learn more about hidden Spark costs, optimizations, and in-motion observability